







Материал статьи основан на актуальных экспертных комментариях в сфере медицинского маркетинга
Основатель и владелец группы компаний консалтинговых услуг по вопросам управления, маркетинга, построения продаж, а также создания медийного контента и презентаций BIECOM
04.02.2026
Дата публикации
04.02.2026
Дата обновления
5 мин.
Время на чтение
61
Просмотров
Содержание
- Введение: Между гуру и реальностью
- Критерии отбора: на что смотреть
- Какие площадки прошли наш аудит?
- Искусство промта: как «поговорить» с нейросетью, чтобы она вас поняла
- Что делать с результатом? Человеческий контроль — это обязательно
- Алгоритм авторского контента
- Итоги и главные выводы
- Часто задаваемые вопросы
Разумное использование нейросетей для создания контента: практическое руководство без иллюзий
Введение: Между гуру и реальностью
Сегодня разговоры о нейросетях напоминают обсуждение погоды: все слышали, многие говорят, но мало кто понимает, как этим реально пользоваться в работе. Особенно когда речь идет о текстовом контенте — статьях, постах, презентационных материалах, которые составляют основу коммуникации любого бизнеса.
Проблема в том, что количество «гуру», внезапно появившихся в сети, катастрофически превышает количество практической, применимой здесь и сейчас информации. Большинство материалов либо слишком теоретичны, либо описывают инструменты, которые в России недоступны без VPN, валютных операций и сомнительных схем. Возникает закономерный вопрос: как же тогда работать?
Я поделюсь своим личным опытом — не как специалист по нейросетям, а как владелец компании, которая ежедневно готовит сложные, наукоемкие текстовые материалы. Мой подход — это максимальный прагматизм. Мы перепробовали огромное количество промтов, переспорили с копирайтерами и дизайнерами и вывели работающую формулу. Если правила не изменятся к сегодняшнему вечеру, то буквально завтра вы сможете создавать качественные текстовые материалы, используя конкретные, доступные инструменты.
Проблема в том, что количество «гуру», внезапно появившихся в сети, катастрофически превышает количество практической, применимой здесь и сейчас информации. Большинство материалов либо слишком теоретичны, либо описывают инструменты, которые в России недоступны без VPN, валютных операций и сомнительных схем. Возникает закономерный вопрос: как же тогда работать?
Я поделюсь своим личным опытом — не как специалист по нейросетям, а как владелец компании, которая ежедневно готовит сложные, наукоемкие текстовые материалы. Мой подход — это максимальный прагматизм. Мы перепробовали огромное количество промтов, переспорили с копирайтерами и дизайнерами и вывели работающую формулу. Если правила не изменятся к сегодняшнему вечеру, то буквально завтра вы сможете создавать качественные текстовые материалы, используя конкретные, доступные инструменты.
Критерии отбора: на что смотреть
Прежде чем доверить нейросети создание контента, необходимо оценить ее по четырем практическим критериям. Это не абстрактные параметры, а фильтры, выведенные через горький опыт проб, ошибок и «перепитий с сотрудниками».
1. Законность и доступность — фундамент, а не опция
Это первый и главный фильтр, который отсекает 80% рекламируемых «гуру» инструментов. Речь не о гипотетической возможности запустить нейросеть где-нибудь «через знакомого». Речь о повседневной работе.
Многие технически сильные зарубежные нейросети находятся в серой зоне с точки зрения законного использования в России. Их полноценное применение упирается в необходимость обхода блокировок (VPN), совершения валютных операций через сомнительные схемы с виртуальными картами и создания условных «левых» аккаунтов. Это не только неудобно, но и рискованно для бизнеса.
Поэтому мы рассматриваем только те площадки, которые можно легально открыть в обычном браузере здесь и сейчас, без скачивания дополнительного ПО и совершения манипуляций. Инструмент должен позволять начать работу с русскоязычным контентом сразу после простой регистрации. Если для старта требуется изучать инструкции по обходу блокировок — это не ваш выбор. Мы говорим только о том, что вы можете открыть браузер, и начать работать.
Многие технически сильные зарубежные нейросети находятся в серой зоне с точки зрения законного использования в России. Их полноценное применение упирается в необходимость обхода блокировок (VPN), совершения валютных операций через сомнительные схемы с виртуальными картами и создания условных «левых» аккаунтов. Это не только неудобно, но и рискованно для бизнеса.
Поэтому мы рассматриваем только те площадки, которые можно легально открыть в обычном браузере здесь и сейчас, без скачивания дополнительного ПО и совершения манипуляций. Инструмент должен позволять начать работу с русскоязычным контентом сразу после простой регистрации. Если для старта требуется изучать инструкции по обходу блокировок — это не ваш выбор. Мы говорим только о том, что вы можете открыть браузер, и начать работать.
2. Практичность — можно ли использовать сегодня?
Второй критерий отсекает красивые, но нефункциональные игрушки. Практичность — это возможность решать задачи сегодня, а не «после прохождения трехмесячного курса».
Инструмент должен работать интуитивно и «из коробки». Если для того, чтобы написать первую статью, вам нужно час изучать специфический синтаксис промтов или проходить многоступенчатую настройку — его практическая ценность для большинства предпринимателей и специалистов близка к нулю.
Нам нужны нейросети, которые понимают запросы на простом, человеческом языке и сразу дают применимый результат. Те самые, про которые можно сказать: «Сегодня вечером вы сможете достаточно просто делать, может быть, не гениальные, но практически доступные и хорошие текстовые материалы». Практичность — это отсутствие барьера между идеей и ее реализацией.
Инструмент должен работать интуитивно и «из коробки». Если для того, чтобы написать первую статью, вам нужно час изучать специфический синтаксис промтов или проходить многоступенчатую настройку — его практическая ценность для большинства предпринимателей и специалистов близка к нулю.
Нам нужны нейросети, которые понимают запросы на простом, человеческом языке и сразу дают применимый результат. Те самые, про которые можно сказать: «Сегодня вечером вы сможете достаточно просто делать, может быть, не гениальные, но практически доступные и хорошие текстовые материалы». Практичность — это отсутствие барьера между идеей и ее реализацией.
3. Оригинальность и «разумность» выдачи
Это ключевой критерий качества. Сможет ли нейросеть осмыслить запрос и выдать не шаблонный набор фраз, а связный, логичный и по-человечески понятный текст?
Можно ввести для этого понятие «Человекоподобное изложение» (ЧПУ). Мой любимый тест — анализ песни «Ветер с моря дул». Примитивная нейросеть выдаст нечто вроде: «в тексте поется про сильный ветер». Это уровень простого пересказа.
Адекватная, «разумная» нейросеть раскроет смысл и образность: «Музыкальное произведение певицы Натали раскрывает образ девушки, вуалирующей сильные эмоциональные переживания через образы погоды, ассоциируя чувства с надвигающейся грозовой бурей».
Если уже в первых строках ответа вы видите подобное смысловое развертывание и интерпретацию — перед вами мощный инструмент. Такой текст — основа для дальнейшей работы. Если же выдача напоминает сухой, тезисный список — нейросеть годится лишь для самой примитивной компиляции данных.
Можно ввести для этого понятие «Человекоподобное изложение» (ЧПУ). Мой любимый тест — анализ песни «Ветер с моря дул». Примитивная нейросеть выдаст нечто вроде: «в тексте поется про сильный ветер». Это уровень простого пересказа.
Адекватная, «разумная» нейросеть раскроет смысл и образность: «Музыкальное произведение певицы Натали раскрывает образ девушки, вуалирующей сильные эмоциональные переживания через образы погоды, ассоциируя чувства с надвигающейся грозовой бурей».
Если уже в первых строках ответа вы видите подобное смысловое развертывание и интерпретацию — перед вами мощный инструмент. Такой текст — основа для дальнейшей работы. Если же выдача напоминает сухой, тезисный список — нейросеть годится лишь для самой примитивной компиляции данных.
4. Универсальность — один инструмент для многих задач
Идеальная площадка — это «комбайн», экономящий время и силы. Вам не нужно переключаться между десятком сервисов для решения смежных задач.
Универсальная нейросеть должна уверенно справляться с несколькими ключевыми функциями:
·Работа с SEO: Во-первых, нейросети прекрасно пишут мета-теги (Title, Description) с нуля по вашему запросу. Просто попросите, и вы получите несколько вариантов. Во-вторых, некоторые из них умеют анализировать чужие сайты. Вы можете задать вопрос: «Какие мета-теги используются на этой странице?» Такую функцию выполняли, на моей памяти, GigaChat, Qwen и Алиса.
Чем больше из этих задач решает одна платформа, тем эффективнее ваш рабочий процесс. Однако важно помнить: в погоне за универсальностью нельзя терять из виду качество выполнения каждой отдельной функции. Иногда лучше использовать две специализированные сети, чем одну посредственную, но «всестороннюю».
Универсальная нейросеть должна уверенно справляться с несколькими ключевыми функциями:
- Написание и рерайт текстов: Создание материалов с нуля и качественная переработка существующих под разные стили и площадки.
- Распознавание текста (OCR): Превращение сканов, фотографий документов (включая плохого качества) в редактируемый текст. По опыту, DeepSeek справляется с этим лучше многих специализированных программ.
- Транскрибация аудио: Преобразование голосовых записей (например, ваших диктовок) в текст. Здесь лидером был GigaChat, но функционал может меняться.
·Работа с SEO: Во-первых, нейросети прекрасно пишут мета-теги (Title, Description) с нуля по вашему запросу. Просто попросите, и вы получите несколько вариантов. Во-вторых, некоторые из них умеют анализировать чужие сайты. Вы можете задать вопрос: «Какие мета-теги используются на этой странице?» Такую функцию выполняли, на моей памяти, GigaChat, Qwen и Алиса.
Чем больше из этих задач решает одна платформа, тем эффективнее ваш рабочий процесс. Однако важно помнить: в погоне за универсальностью нельзя терять из виду качество выполнения каждой отдельной функции. Иногда лучше использовать две специализированные сети, чем одну посредственную, но «всестороннюю».
Какие площадки прошли наш аудит?
Перебрав множество вариантов — и американских, и китайских, — мы выделили несколько реально рабочих решений, соответствующих нашим критериям.

Российские разработки
GigaChat от Сбера и Алиса (Яндекс) — это национальные ИИ-флагманы, к которым по умолчанию обращаются многие пользователи в России. Однако, тут можно выделить ряд системных недостатков, которые существенно ограничивают их применение для создания качественного контента.
GigaChat от Сбера и Алиса (Яндекс) — это национальные ИИ-флагманы, к которым по умолчанию обращаются многие пользователи в России. Однако, тут можно выделить ряд системных недостатков, которые существенно ограничивают их применение для создания качественного контента.
Главная проблема: «роботизированная» шаблонность и переструктуризация
Самый яркий критический аргумент — неестественная, избыточная структура генерируемого текста - «фактор переструктуризации». Нейросеть выдает текст, который слишком правильный. Он разбит на идеально ровные абзацы, содержит множество однотипных подзаголовков (H2, H3), расставленных с механической регулярностью. Каждый раздел имеет схожий объем и построение. Обычный человек так не пишет. Такая текстура сразу выдает машинную генерацию. Она лишает текст естественной динамики, живого ритма и индивидуальности. Для читателя это часто скучно и вызывает отторжение. Такая шаблонность —показатель недоработки программного продукта. Вместо глубокой семантической обработки и создания связного нарратива, нейросеть заполняет готовую схему тезисами. Это уровень продвинутого автозаполнения, а не интеллектуального соавторства.
Ключевые недостатки на практике
1.Слабая работа с контекстом и «разумностью». На примере теста с песней «Ветер с моря дул» российские сети показывают худшие результаты. Они склонны давать примитивные, поверхностные ответы («поется про ветер»), не улавливая смысловых слоев, метафор и эмоциональной окраски.
2.Проблемы с обработкой сложных промтов и аудио. GigaChat какое-то время был лидером в транскрибации аудио, хорошо справляясь с длинными «грязными» записями. Однако эта функция была нестабильна, появились подозрения, что её могут заблокировать или ограничить. Это иллюстрирует общую проблему непредсказуемости — функционал может внезапно исчезнуть.
3.Склонность к сокращению текста. Российские нейросети очень любят все сокращать. Даже при четком указании нужного объема в промте (например, 8000 знаков) они зачастую выдают текст значительно короче, что вынуждает пользователя искусственно завышать требуемый объем в запросе.
На данном этапе практическая ценность GigaChat и Алиса для профессиональной работы с текстом сильно ограничена.
Они могут быть полезны для:
Китайские платформы
Признаюсь честно, когда я только начинал погружаться в тему, мои ожидания были довольно предсказуемыми. Я думал, что буду сравнивать американские гиганты с нашими отечественными разработками. Реальность оказалась куда интереснее. После месяцев тестов, проб и ошибок моими основными рабочими инструментами стали две китайские платформы: DeepSeek и Qwen от Alibaba. И вот почему это произошло.
Первое и главное: они понимают «по-русски» — не только слова, но и смыслы
Самый яркий пример, который я всегда привожу — это тест на «разумность». Помните историю с песней «Ветер с моря дул»? Когда я задаю этот вопрос примитивной нейросети, она выдает что-то вроде сухого пересказа: «в тексте поется о ветре».
DeepSeek же отвечает иначе. Он видит за метафорой живые эмоции: «Музыкальное произведение раскрывает эмоциональные переживания через образы погоды, ассоциируя чувства с надвигающейся грозовой бурей». Разница — как между человеком, который механически повторяет услышанное, и человеком, который способен прочувствовать и интерпретировать. Именно эта способность к осмыслению делает текст живым и ценным.
Второе: они не выдают текст-«конструктор»
В отличие от некоторых российских аналогов, которые грешат шаблонной, излишне идеальной структурой (тот самый фактор переструктуризации), китайские сети выдают текст, который звучит естественно. В нем есть логика, но нет ощущения, что его собрал робот по инструкции. Абзацы могут быть разной длины, ритм — живым, подача — свободной. Это критически важно, когда ты создаешь контент для людей, а не для роботов-поисковиков.
Третье: это настоящие «рабочие лошадки» с конкретными суперспособностями
Мой выбор пал на эти платформы не из-за рекламы, а потому что они реально решают мои ежедневные задачи лучше других.
·DeepSeek — мой чемпион по распознаванию. Мне часто нужно оцифровать сканы договоров, фотографии документов, даже плохо читаемые рукописные листы. Так вот, DeepSeek справляется с этой задачей лучше, чем лицензионный Adobe Fine Reader — это не голословное заявление, а результат моего личного сравнения. Загружаешь изображение — получаешь идеально структурированный текст. Это экономит часы работы.
·Они отличные «секретари» для авторского контента. Мой любимый метод создания статей — сначала надиктовать мысли в аудио, а потом обработать. Qwen, например, отлично справляется с транскрибацией коротких аудио. А DeepSeek потом превращает эту «сырую» расшифровку в выверенный, структурированный текст, сохраняя при этом мою мысль и стиль. Это не плагиат, а усиление моей собственной экспертизы.
·Они пишут отличные SEO-теги. Попроси их сгенерировать Title и Description для статьи — результат будет релевантным и цепляющим. При этом DeepSeek, что важно, отлично пишет теги, но не анализирует чужие сайты — видимо, политика такая. Зато другие задачи выполняет блестяще.
·Четвертое и самое практичное: они ДОСТУПНЫ здесь и сейчас. Это не менее важно, чем качество. Мне не нужно искать VPN, заводить виртуальные карты для валютных платежей или создавать аккаунты на сомнительных сервисах. Я открываю браузер, регистрируюсь за пару минут — и начинаю работать. В условиях постоянной нехватки времени это решающий фактор.
Мой итог:
Если бы меня спросили: «С чего начать работу с нейросетями для контента сегодня?» — мой ответ был бы однозначным. Не с просмотра вебинаров очередного «гуру», а с простых действий:
1.Откройте в браузере DeepSeek.
2.Зарегистрируйтесь за две минуты.
3.Попробуйте дать ему свой первый осмысленный промт.
Эти платформы не идеальны. У них тоже есть свои ограничения. Но на сегодняшний день это самый прямой и качественный путь от идеи до готового текста. Они доказали своей работой, что география разработки не так важна, как умение нейросети понимать контекст, чувствовать язык и честно выполнять свою работу. И с этой работой они справляются на удивление хорошо.
2.Проблемы с обработкой сложных промтов и аудио. GigaChat какое-то время был лидером в транскрибации аудио, хорошо справляясь с длинными «грязными» записями. Однако эта функция была нестабильна, появились подозрения, что её могут заблокировать или ограничить. Это иллюстрирует общую проблему непредсказуемости — функционал может внезапно исчезнуть.
3.Склонность к сокращению текста. Российские нейросети очень любят все сокращать. Даже при четком указании нужного объема в промте (например, 8000 знаков) они зачастую выдают текст значительно короче, что вынуждает пользователя искусственно завышать требуемый объем в запросе.
На данном этапе практическая ценность GigaChat и Алиса для профессиональной работы с текстом сильно ограничена.
Они могут быть полезны для:
- Простейших задач, где достаточно шаблонного текста.
- Ситуаций, где принципиально важен выбор отечественного продукта.
- Экспериментов и базового знакомства с принципами генерации.
Китайские платформы
Признаюсь честно, когда я только начинал погружаться в тему, мои ожидания были довольно предсказуемыми. Я думал, что буду сравнивать американские гиганты с нашими отечественными разработками. Реальность оказалась куда интереснее. После месяцев тестов, проб и ошибок моими основными рабочими инструментами стали две китайские платформы: DeepSeek и Qwen от Alibaba. И вот почему это произошло.
Первое и главное: они понимают «по-русски» — не только слова, но и смыслы
Самый яркий пример, который я всегда привожу — это тест на «разумность». Помните историю с песней «Ветер с моря дул»? Когда я задаю этот вопрос примитивной нейросети, она выдает что-то вроде сухого пересказа: «в тексте поется о ветре».
DeepSeek же отвечает иначе. Он видит за метафорой живые эмоции: «Музыкальное произведение раскрывает эмоциональные переживания через образы погоды, ассоциируя чувства с надвигающейся грозовой бурей». Разница — как между человеком, который механически повторяет услышанное, и человеком, который способен прочувствовать и интерпретировать. Именно эта способность к осмыслению делает текст живым и ценным.
Второе: они не выдают текст-«конструктор»
В отличие от некоторых российских аналогов, которые грешат шаблонной, излишне идеальной структурой (тот самый фактор переструктуризации), китайские сети выдают текст, который звучит естественно. В нем есть логика, но нет ощущения, что его собрал робот по инструкции. Абзацы могут быть разной длины, ритм — живым, подача — свободной. Это критически важно, когда ты создаешь контент для людей, а не для роботов-поисковиков.
Третье: это настоящие «рабочие лошадки» с конкретными суперспособностями
Мой выбор пал на эти платформы не из-за рекламы, а потому что они реально решают мои ежедневные задачи лучше других.
·DeepSeek — мой чемпион по распознаванию. Мне часто нужно оцифровать сканы договоров, фотографии документов, даже плохо читаемые рукописные листы. Так вот, DeepSeek справляется с этой задачей лучше, чем лицензионный Adobe Fine Reader — это не голословное заявление, а результат моего личного сравнения. Загружаешь изображение — получаешь идеально структурированный текст. Это экономит часы работы.
·Они отличные «секретари» для авторского контента. Мой любимый метод создания статей — сначала надиктовать мысли в аудио, а потом обработать. Qwen, например, отлично справляется с транскрибацией коротких аудио. А DeepSeek потом превращает эту «сырую» расшифровку в выверенный, структурированный текст, сохраняя при этом мою мысль и стиль. Это не плагиат, а усиление моей собственной экспертизы.
·Они пишут отличные SEO-теги. Попроси их сгенерировать Title и Description для статьи — результат будет релевантным и цепляющим. При этом DeepSeek, что важно, отлично пишет теги, но не анализирует чужие сайты — видимо, политика такая. Зато другие задачи выполняет блестяще.
·Четвертое и самое практичное: они ДОСТУПНЫ здесь и сейчас. Это не менее важно, чем качество. Мне не нужно искать VPN, заводить виртуальные карты для валютных платежей или создавать аккаунты на сомнительных сервисах. Я открываю браузер, регистрируюсь за пару минут — и начинаю работать. В условиях постоянной нехватки времени это решающий фактор.
Мой итог:
Если бы меня спросили: «С чего начать работу с нейросетями для контента сегодня?» — мой ответ был бы однозначным. Не с просмотра вебинаров очередного «гуру», а с простых действий:
1.Откройте в браузере DeepSeek.
2.Зарегистрируйтесь за две минуты.
3.Попробуйте дать ему свой первый осмысленный промт.
Эти платформы не идеальны. У них тоже есть свои ограничения. Но на сегодняшний день это самый прямой и качественный путь от идеи до готового текста. Они доказали своей работой, что география разработки не так важна, как умение нейросети понимать контекст, чувствовать язык и честно выполнять свою работу. И с этой работой они справляются на удивление хорошо.
Искусство промта: как «поговорить» с нейросетью, чтобы она вас поняла
Ключевой навык работы с нейросетью — составление промта (запроса). Это не магия, а строгая архитектура. Правильный промт — это техническое задание (ТЗ).
Архитектура эффективного промта:
Архитектура эффективного промта:

Если вам интересно, как применять технологии для создания качественного контента именно в медицинской тематике, подробную методику — от анализа интентов до построения графов знаний — вы можете найти в статье «"Промтоведение": как получить контент для медицинского сайта из нейросетей» от SEO-специалиста и основателя веб студии SOVA-DIGITAL.COM Андрея Зимихина.
Что делать с результатом? Человеческий контроль — это обязательно
Когда нейросеть выдаёт вам текст, работа только начинается. Вот мой алгоритм, выверенный практикой.
Сначала — «проверка на разумность».
Я просто читаю первые абзацы и задаю себе вопрос: это связное повествование или сухое перечисление фактов? Как я говорил, для меня индикатор — способность сети к «Человекоподобному изложению» (ЧПУ). Если текст с первых строк показывает не просто пересказ, а осмысление, как в примере с песней — «раскрывает эмоциональные переживания через образы» — это хороший знак. Значит, есть над чем работать. Если же вижу просто набор тезисов, значит, сеть не справилась с глубиной.
Затем — «структурная проверка».
Это критически важно. Я сразу смотрю на то, как текст разбит на части. Если вижу слишком идеальную, шаблонную структуру — «все правильно разбито, на правильное количество равных абзацев» — это тот самый фактор переструктуризации, главный индикатор машинной генерации. Так нормальные люди не пишут. Такой текст нужно вручную «ломать»: склеивать излишне дробные абзацы, убирать лишние подзаголовки, добавлять живые переходы. Если структура «too much», используйте такой текст нельзя без серьезной правки.
Обязательно — проверка терминологии и фактов.
Здесь правило простое: не доверяйте. Нейросети любят фантазировать. Все цифры, имена, специальные термины должны быть перепроверены вами. Сеть — не эксперт, она умеет очень убедительно компоновать информацию, в том числе и выдуманную.
Если результат плох — не бросайте сеть, меняйте подход.
Я никогда не спешу винить нейросеть — в 99% случаев проблема в самом промте, в том, как я поставил задачу. Поэтому я не бросаю сеть, а начинаю экспериментировать с формулировками. Во-первых, просто меняю слова в запросе: синонимы творят чудеса. Фраза «детальный обзор» вместо сухого «статья» или «развернутый анализ» вместо «текст» может кардинально изменить результат. Во-вторых, я меняю сами блоки промта: указываю другой стиль изложения или объем, прошу написать не как классическую статью, а, например, как расшифровку живого выступления.
И мой главный рабочий принцип — никогда не зацикливаться на одной площадке. Как я убедился, каждая сеть со временем начинает выдавать повторы. Поэтому я даю одно и то же задание сразу нескольким платформам — например, DeepSeek, Qwen и GigaChat — а затем, как редактор, собираю из разных ответов идеальный конструктор, беру из каждого варианта самые сильные части.Нейросеть — это мощный генератор сырого материала. Но последнее слово, смысловая выверенность и ответственность за каждую цифру всегда остаются за человеком. Без этого этапа работа с ИИ теряет всякий смысл.
Сначала — «проверка на разумность».
Я просто читаю первые абзацы и задаю себе вопрос: это связное повествование или сухое перечисление фактов? Как я говорил, для меня индикатор — способность сети к «Человекоподобному изложению» (ЧПУ). Если текст с первых строк показывает не просто пересказ, а осмысление, как в примере с песней — «раскрывает эмоциональные переживания через образы» — это хороший знак. Значит, есть над чем работать. Если же вижу просто набор тезисов, значит, сеть не справилась с глубиной.
Затем — «структурная проверка».
Это критически важно. Я сразу смотрю на то, как текст разбит на части. Если вижу слишком идеальную, шаблонную структуру — «все правильно разбито, на правильное количество равных абзацев» — это тот самый фактор переструктуризации, главный индикатор машинной генерации. Так нормальные люди не пишут. Такой текст нужно вручную «ломать»: склеивать излишне дробные абзацы, убирать лишние подзаголовки, добавлять живые переходы. Если структура «too much», используйте такой текст нельзя без серьезной правки.
Обязательно — проверка терминологии и фактов.
Здесь правило простое: не доверяйте. Нейросети любят фантазировать. Все цифры, имена, специальные термины должны быть перепроверены вами. Сеть — не эксперт, она умеет очень убедительно компоновать информацию, в том числе и выдуманную.
Если результат плох — не бросайте сеть, меняйте подход.
Я никогда не спешу винить нейросеть — в 99% случаев проблема в самом промте, в том, как я поставил задачу. Поэтому я не бросаю сеть, а начинаю экспериментировать с формулировками. Во-первых, просто меняю слова в запросе: синонимы творят чудеса. Фраза «детальный обзор» вместо сухого «статья» или «развернутый анализ» вместо «текст» может кардинально изменить результат. Во-вторых, я меняю сами блоки промта: указываю другой стиль изложения или объем, прошу написать не как классическую статью, а, например, как расшифровку живого выступления.
И мой главный рабочий принцип — никогда не зацикливаться на одной площадке. Как я убедился, каждая сеть со временем начинает выдавать повторы. Поэтому я даю одно и то же задание сразу нескольким платформам — например, DeepSeek, Qwen и GigaChat — а затем, как редактор, собираю из разных ответов идеальный конструктор, беру из каждого варианта самые сильные части.Нейросеть — это мощный генератор сырого материала. Но последнее слово, смысловая выверенность и ответственность за каждую цифру всегда остаются за человеком. Без этого этапа работа с ИИ теряет всякий смысл.
Алгоритм авторского контента
Это мой личный метод создания по-настоящему уникальных текстов для блога и сайта. Он честный и эффективный.
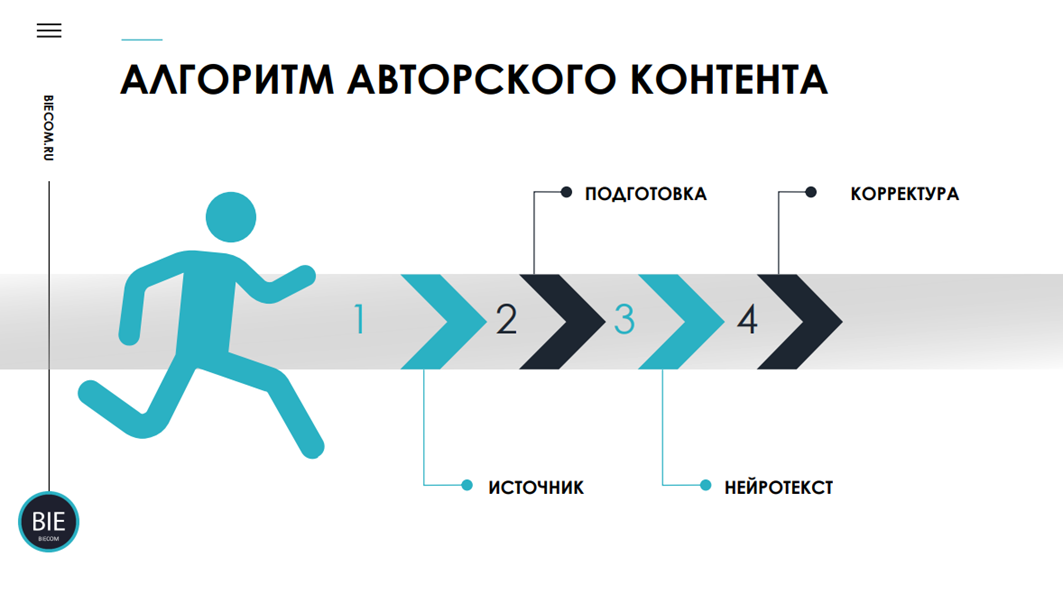
1.Источник — вы. У вас нет времени писать? Говорите. Возьмите диктофон в телефоне. Составьте простой контент-план в блокноте и в свободную минуту (в машине, в парке) записывайте свои мысли по теме. Не стремитесь к идеалу — допускайте паузы, запинки. Ваша задача — вылить в аудио поток мыслей на 10-30 минут.
2.Подготовка — транскрибация. Загрузите этот «грязный» аудиофайл в нейросеть с функцией транскрибации (распознавания аудио в текст). Раньше это отлично делал GigaChat. Qwen справляется с файлами до 3 минут.
3.Нейрообработка. Полученную текстовую расшифровку (сырой, неотредактированный текст) загружаете в мощную нейросеть, например, DeepSeek. Пишете промт: «Отредактируй и приведи в порядок эту расшифровку. Сделай статью для сайта в публицистическом стиле, объемом 5000 знаков». Нейросеть уберет мусор, выстроит структуру, сгладит шероховатости.
4.Финальная корректура. Вы читаете и вносите последние правки, добавляете личные нотки.
В этой схеме нейросеть — ваш интеллектуальный секретарь. Она не придумывает мысли за вас, а технически обрабатывает ваши идеи, экономя вам часы рутинной работы. Текст остается авторским, но создается в разы быстрее.
2.Подготовка — транскрибация. Загрузите этот «грязный» аудиофайл в нейросеть с функцией транскрибации (распознавания аудио в текст). Раньше это отлично делал GigaChat. Qwen справляется с файлами до 3 минут.
3.Нейрообработка. Полученную текстовую расшифровку (сырой, неотредактированный текст) загружаете в мощную нейросеть, например, DeepSeek. Пишете промт: «Отредактируй и приведи в порядок эту расшифровку. Сделай статью для сайта в публицистическом стиле, объемом 5000 знаков». Нейросеть уберет мусор, выстроит структуру, сгладит шероховатости.
4.Финальная корректура. Вы читаете и вносите последние правки, добавляете личные нотки.
В этой схеме нейросеть — ваш интеллектуальный секретарь. Она не придумывает мысли за вас, а технически обрабатывает ваши идеи, экономя вам часы рутинной работы. Текст остается авторским, но создается в разы быстрее.
Итоги и главные выводы
В завершение хочу подвести итог:
Нейросеть — это не волшебный чёрный ящик, который напишет всё за вас. Это скорее очень способный и быстрый помощник, интеллектуальный инструмент. Её ценность раскрывается только в тандеме с человеком. Поэтому идея уволить копирайтеров и отдать всё на откуп искусственному интеллекту — это путь в никуда. Без вашего контроля, вашей экспертизы и финальной правки нейросеть может наделать больше ошибок, чем принести пользы.
Никогда не забывайте о главном правиле: любой текст, созданный нейросетью, требует вашего внимательного прочтения и редактирования. Проверяйте факты, «ломайте» слишком правильную, шаблонную структуру, оценивайте текст на «разумность». Нейросети обладают богатой фантазией и могут очень убедительно «дорисовывать» детали, которых не существует.
Имейте в виду, что этот мир меняется не по дням, а по часам. Функции, которые были доступны вчера, могут исчезнуть или стать платными уже завтра. Нужно оставаться гибким и быть готовым адаптировать свой рабочий процесс.
И последнее, о чём стоит говорить честно. Если отбросить эмоции и посмотреть на сухие результаты тестов, то сегодня, к сожалению, российские нейросетевые продукты для работы с текстом ещё значительно отстают от зарубежных аналогов.
Но самый важный вывод простой: не бойтесь начать. Прямо сегодня откройте DeepSeek, потратьте минуту на регистрацию и попробуйте написать свой первый осмысленный промт.
Нейросеть — это не волшебный чёрный ящик, который напишет всё за вас. Это скорее очень способный и быстрый помощник, интеллектуальный инструмент. Её ценность раскрывается только в тандеме с человеком. Поэтому идея уволить копирайтеров и отдать всё на откуп искусственному интеллекту — это путь в никуда. Без вашего контроля, вашей экспертизы и финальной правки нейросеть может наделать больше ошибок, чем принести пользы.
Никогда не забывайте о главном правиле: любой текст, созданный нейросетью, требует вашего внимательного прочтения и редактирования. Проверяйте факты, «ломайте» слишком правильную, шаблонную структуру, оценивайте текст на «разумность». Нейросети обладают богатой фантазией и могут очень убедительно «дорисовывать» детали, которых не существует.
Имейте в виду, что этот мир меняется не по дням, а по часам. Функции, которые были доступны вчера, могут исчезнуть или стать платными уже завтра. Нужно оставаться гибким и быть готовым адаптировать свой рабочий процесс.
И последнее, о чём стоит говорить честно. Если отбросить эмоции и посмотреть на сухие результаты тестов, то сегодня, к сожалению, российские нейросетевые продукты для работы с текстом ещё значительно отстают от зарубежных аналогов.
Но самый важный вывод простой: не бойтесь начать. Прямо сегодня откройте DeepSeek, потратьте минуту на регистрацию и попробуйте написать свой первый осмысленный промт.
Подробнее разобраться в маркетинге в медицине, вы сможете на онлайн курсе «Медицинский маркетинг» для руководителей медицинских организаций в Школе Медицинского Бизнеса https://medicalbusinesschool.com/marketing
Понравилась статья?
Мнение автора

Часто задаваемые вопросы
На сегодняшний день наиболее стабильными и эффективными для работы с русскоязычным контентом показали себя две китайские платформы: DeepSeek и Qwen (от Alibaba). Они до-ступны для простой регистрации, не требуют обхода блокировок и показывают лучшее ка-чество «разумной» обработки текста по сравнению с текущими российскими аналогами.
Ключ — в чёткой структуре промта. Начните с цели: «для сайта» или «для Telegram». Укажи-те точный объём в знаках (с запасом 20–30%, так как сети любят сокращать). Детально опи-шите тему и контекст, задайте стиль (например, «экспертно-аналитический»). Для сложных задач прикрепляйте файл с терминами и тезисами — нейросеть отлично использует вашу исходную информацию.
Нет, и это опасное заблуждение. Нейросеть — это мощный помощник для генерации черно-виков, рерайта или обработки сырых данных. Но финальная проверка фактов, «разумности» текста, адаптация структуры под живую речь и стратегическая редактура остаются за чело-веком. Без контроля результат будет шаблонным, а иногда и содержащим выдуманные данные.
Другие статьи